Written by – Manish Juneja
Project Purpose
The objective is to establish an enterprise Data Lake that streamlines data management and fulfills growing consumption and analytical requirements. The solution involves implementing an AWS data lake, which ensures secure, reliable, and easily accessible storage for structured and unstructured data of any scale. The infrastructure as code (IaC) methodology is utilized to construct the entire solution in conjunction with a CI/CD strategy.
Before Setup
Previous customers faced limitations with conventional data storage and analytical tools, as they lacked the agility, scalability, and flexibility to generate valuable business insights. The system required significant manual intervention and imposed substantial operational overhead.
Approach finalized
An enterprise data lake solution is required to centrally manage data assets, enable automated ingestion, enable consistent consumption patterns, and implement security guardrails.
AWS offers Lake Formation, a pre-packaged service that integrates centralized access management on the AWS platform, allowing for faster establishment of a data lake. This service facilitates data searching, sharing, transformation, analysis, and governance within an organization or with external users.
Architecture overview
The high-level AWS cloud architecture is shown in the below diagram. The necessary AWS services are provisioned using this information.
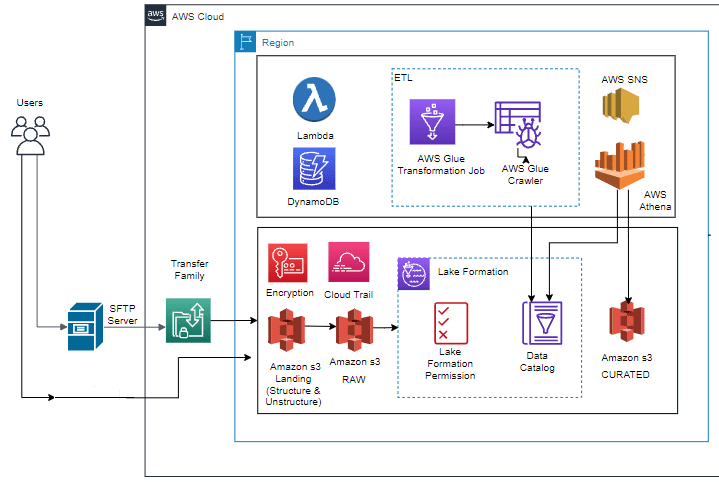
Solution Components
The proposed solution leverages the Terraform IaC tool to automate the creation of the entire platform on the AWS Cloud. Subsequently, distinct AWS code pipelines are established for each environment (DEV/TEST/PROD). Each pipeline is responsible for deploying the corresponding Terraform code for its respective environment. The following AWS services can be provisioned and configured using the Terraform code to construct a data lake solution on the AWS Cloud.
· S3 Buckets
The solution uses Amazon S3 buckets, which allow for the storage of unlimited cloud files and datasets. Multiple S3 buckets will be created, including landing, raw, and curated buckets to accommodate different datasets. The landing bucket will house all unstructured data, serving as a secure temporary storage location for incoming source files. After the validation tests, the data from the landing bucket is transferred to the raw bucket. The raw bucket provides secure storage for data in its original, unaltered state. Data processing operations will be performed on the data residing in the raw bucket. Once the analysis and conversion processes are completed, the processed data will be loaded into a curated bucket.
· AWS Transfer family
This solution configures a fully managed and secure transfer family that scales in real-time to meet your needs, enabling you to transfer files into and out of Amazon Simple Storage Service (Amazon S3) storage with respect to achieving data-in-transit encryption.
All unstructured data from different sources will be loaded into the landing S3 bucket using the transfer family service.
· AWS KMS
You can make, maintain, and exercise control over cryptographic keys using AWS Key Management Service (AWS KMS). AWS KMS keys are used to encrypt Amazon S3 objects. As a result, the KMS keys are used to encrypt the data at rest.
· Lake Formation
The solution configures lake formation. It is a fully managed service that makes building, securing, and managing data lakes easier. It can gather and store data at any scale for a reasonable price. It secures the data and prevents unauthorized access. It enables scalable, centralized management of fine-grained access for internal and external clients/consumers at the table and column levels.
· AWS Glue
The approach utilizes AWS Glue to make data within the data lake discoverable and enables extract, transform, and load (ETL) capabilities for data preparation before analysis. Glue creates a unified metadata repository, a data catalog encompassing various data sources. The solution will employ Glue crawlers for each data source and schedule daily scans to monitor changes. The ETL glue jobs can be planned and executed using the glue workflows to transform data.
· AWS Athena
Using common SQL queries, this solution configures Athena to simplify analyzing data directly in Amazon S3. Users can query curated data in a SQL fashion with Athena thanks to its integration with AWS Glue Data Catalog.
· DynamoDB
It is a fully managed service for NoSQL databases. The Data Lake uses Amazon DynamoDB tables on AWS solution to store metadata for the data packages, configuration options, and user items.
· AWS Lambda
To execute glue jobs and subsequent crawlers, this system uses Lambda to start Glue Workflows. Lambda allows code to be executed without server provisioning or management.
· AWS SNS
SNS is a user-friendly web service that simplifies cloud notifications’ setup, utilization, and delivery. SNS notifications are utilized to inform recipients at each stage of data processing about various processing steps.
Summary
The setting up of an enterprise data lake on the AWS Cloud was discussed in this post. However, this is just the beginning, as every time a situation, requirement, cost, team skill, or new service offered by cloud platforms changes, there are many more aspects to consider and adapt to.



