Modern cloud applications often struggle when components are tightly coupled, one slow module can block the entire flow, or a single failure can cascade across services. That’s where a reliable message queuing service helps. In this article, we dive into what is AWS SQS, how it solves these issues, and how you can set it up to build scalable, resilient systems.
What is AWS SQS? Benefits of Using It
Amazon SQS (Simple Queue Service) is a fully managed message‑queuing service offered by Amazon Web Services. It enables different parts of a distributed application, producers and consumers, to communicate asynchronously by sending, storing, and receiving messages via queues. In doing so, SQS decouples application components so they don’t have to directly depend on each other’s availability, processing speed, or uptime.
Benefits
- High durability and reliability – SQS stores messages redundantly across multiple servers/availability zones so that data loss is highly unlikely even if there are hardware failures. (AWS Documentation)
- Massive scalability on demand – SQS automatically handles scaling: it can buffer virtually any number of messages, adjusting to workload spikes without manual provisioning.
- Reduced operational overhead – As a fully managed service, AWS handles infrastructure, maintenance, scaling, and reliability. You don’t need to run or manage your own message‑queue servers.
- Security and flexibility – Message payloads are encrypted via server‑side encryption with AWS Key Management, helping protect sensitive data during queue storage and transit.
- Flexible message handling – Features such as batching (send/receive up to 10 messages at a time), long polling, dead‑letter queues, and visibility timeout make SQS fit for a variety of use‑cases like asynchronous jobs, retries, load smoothing, and error handling.
Because of these benefits, SQS is a solid choice when building microservices, serverless, or distributed architectures that require loose coupling, fault-tolerance, and scalability.
Disadvantages or Limitations of AWS SQS
While SQS offers many advantages, it comes with trade‑offs and limitations that you should keep in mind before using it.
- Message ordering isn’t guaranteed in Standard queues – If you use the default (Standard) type, messages may arrive out of order, and duplicates are possible. This makes it unsuitable when strict ordering or exactly‑once processing matters.
- Possible duplicate delivery – Because Standard queues provide “at-least-once” delivery, a message might be delivered more than once. Your application must be able to handle repeated processing gracefully.
- Message size limitation – SQS supports up to 256 KB per message payload. If you need to queue larger data, you need to split the data or use an external store (e.g. store in S3 and pass pointer via SQS).
- Latency and polling overhead – SQS is pull‑based: consumers poll for messages. If polling is frequent and many requests return empty, this can cause inefficiency. Improper polling intervals may also increase cost. Long‑polling and batching help, but they add complexity.
- Cost under high volume/poor usage patterns – With large number of messages, large payloads, or inefficient polling, costs can increase.
In short: while SQS simplifies message queuing, you need careful design and coding practices (idempotency, correct queue type, optimal polling) to avoid pitfalls.
How Does Amazon SQS Work?
Let’s explain SQS’s workflow using a simple example: imagine an e‑commerce platform processing customer orders.
- Order Placed (Producer) – When a user submits an order, your application (producer) sends the order details, as a message to an SQS queue.
- Message Stored in Queue – SQS receives the message and stores it durably (across multiple servers/zones). It becomes available for consumers to fetch.
- Consumer Polls Queue – A background worker (consumer) periodically polls the queue (or listens) for messages. When it picks up a message, SQS “locks” it so that other consumers can’t process the same message concurrently. This is controlled by visibility timeout. (AWS Documentation)
- Process the Message – The consumer processes the order: payment, inventory update, sending confirmation email, etc.
- Delete the Message – After successful processing, the consumer deletes the message from the queue. If processing fails or doesn’t complete before the visibility timeout ends, the message becomes visible again for reprocessing.
Because of this asynchronous, decoupled approach, the user placing the order doesn’t have to wait for the entire processing chain. The system remains responsive and fault‑tolerant.
This model:
Produce → Queue → Consume → Delete — lets you build scalable pipelines with many producers and consumers working independently.
Types of AWS SQS & Choosing the Right Type
Amazon SQS offers two main queue types. Choosing the right type depends on your application’s requirements: throughput vs ordering & duplication guarantees.
Standard Queues
- Provide very high throughput: effectively unlimited messages per second; ideal for high‑volume workloads.
- Provide at‑least-once delivery: messages will be delivered, but there is a possibility of duplicates.
- Ordering is best effort: messages may arrive out of order.
- Suitable when throughput matters more than strict ordering or duplicates: bulk processing, logging, notifications, background tasks.
FIFO Queues (First-In-First-Out)
- Guarantee strict ordering and exactly‑once processing (when using message group IDs or deduplication).
- Prevent duplicate messages; useful for workflows where duplication or order mistakes are unacceptable.
- Throughput is lower than Standard by default (e.g. 300 send/receive/delete operations per second). With batching you can reach up to ~3,000 messages/sec.
- More suitable when message order and processing accuracy matter; e.g. financial transactions, inventory updates, sequential workflows, ordered events.
Which to choose?
- If your application demands high message throughput and can tolerate occasional duplicates or out‑of-order delivery, use Standard queue.
- If you need guaranteed ordering and no duplicates, for critical workflows where correctness matters; use FIFO queue.
How to Use Amazon SQS: A Step-by-Step Guide
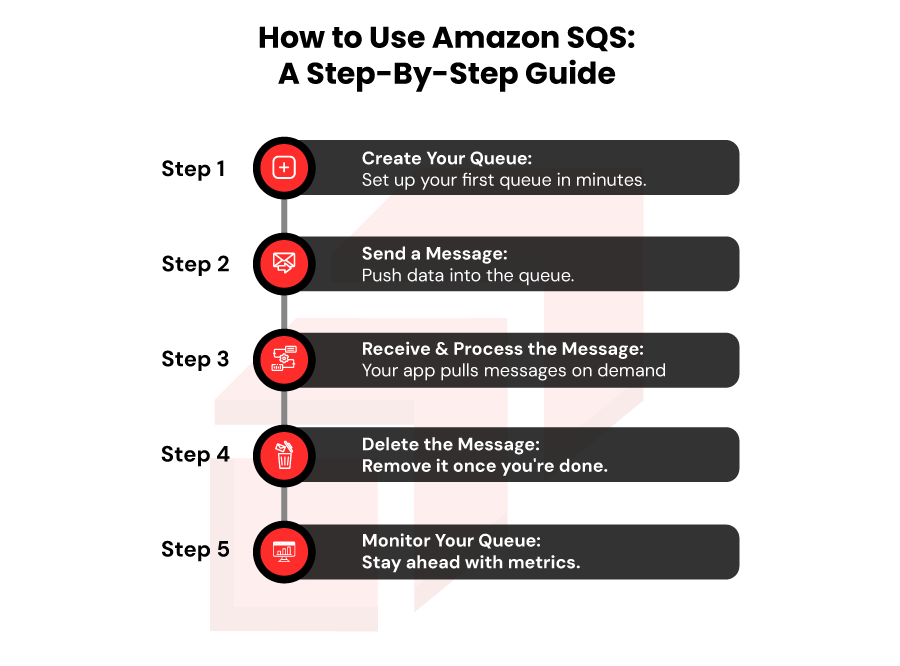
Here is a practical, step‑by‑step guide to get started with Amazon SQS, from setup to message processing.
Step 1: Create Your Queue
- Log in to the AWS Management Console, search for “SQS” and open the SQS dashboard.
- Click “Create queue”. Choose the queue type: Standard (default) or FIFO (requires queue name ending in. fifo).
- Customize settings: visibility timeout, message retention period (1 minute to 14 days), delivery delay, max message size (default 256 KB), etc. Then click Create queue.
Step 2: Send a Message
- Use the AWS Console, AWS CLI, or SDK to send a message. Provide a message body. Remember payload limit: up to 256 KB per message. For larger data, consider storing payload in external storage (like S3) and send only references.
Step 3: Receive and Process the Message
- The consumer polls the queue (ReceiveMessage API) to fetch messages. Once a message is received, it becomes invisible for the configured visibility timeout, ensuring no other consumer processes it concurrently.
- The consumer processes the message: for example, executes business logic, updates databases, triggers other services, etc.
Step 4: Delete the Message
- After successful processing, call DeleteMessage (using the receipt handle) to remove the message permanently from the queue. If you don’t delete it before visibility timeout, the message becomes visible again, enabling retries (or duplicates).
Step 5: Monitor Your Queue
- Keep an eye on your queues through the AWS Console or by piping metrics into Amazon CloudWatch. Track things like messages sent and received, queue depth, the age of the oldest message, and any processing errors. These signals make it easier to spot slowdowns early and understand where your system might be getting stuck.
This simple workflow covers most common usage patterns: producers enqueue tasks, consumers process tasks asynchronously, and both scale independently.
What Is Amazon SQS Used For? Practical Use Cases
Here are common real‑world scenarios where Amazon SQS is extremely useful:
Decoupling Microservices
In microservices architectures, different services often need to communicate asynchronously. SQS lets one service enqueue a message (task/request) that another service processes later; without requiring both to be online or synchronized. This decoupling improves fault tolerance and flexibility.
Managing Task Backlogs
For workloads that spike or accumulate; e.g. image processing, sending emails, generating reports, SQS acts as a buffer. Producers can quickly enqueue tasks without waiting; workers consume them at their own pace. This smooths load and avoids overloading any component.
Scheduling Batch Jobs & Asynchronous Workflows
SQS is ideal for orchestrating batch jobs, data processing, analytics, and other asynchronous workflows. For example: data ingestion pipelines, log collection, cleanup tasks, scheduled jobs; where you don’t need immediate processing but require reliable delivery.
Beyond that, SQS works well for order processing systems (e-commerce orders), notifications, decoupled event processing, rate‑limited workloads or burst traffic handling, and integrating with other AWS services.
Build Your Scalable SQS Application with Rapyder
If you want to leverage AWS SQS for your projects but prefer expert guidance, that’s where a cloud‑services partner like Rapyder can help.
Rapyder offers end-to-end AWS consulting: from designing a queue‑based architecture, choosing the right queue type, configuring advanced features, to integrating SQS with other AWS services (e.g. AWS Lambda, S3, DynamoDB).
With Rapyder’s help, you can avoid common pitfalls; such as message duplication, incorrect visibility settings, unoptimized polling, or cost overruns, and build robust, scalable, and cost‑effective distributed applications.
Conclusion
With features like high durability, automatic scaling, encryption, batching, and flexibility between Standard and FIFO queue types, SQS fits a wide range of use cases – from decoupled microservices and background job processing to batch workloads, asynchronous tasks, and event-driven systems.
However, it’s important to consider trade‑offs: message ordering, duplicates, message size limits, latency, and cost under heavy load. With proper design, idempotent consumers, correct queue type, message size management, batching, and monitoring, you can unlock the full potential of SQS.
Whether you are building a small application or a large distributed system, AWS SQS remains a go-to choice for reliable, scalable messaging. And with support from a skilled AWS partner like Rapyder, you can set up your system efficiently and confidently.





